Videocore GPU (v3d)
Key references
https://dri.freedesktop.org/docs/drm/gpu/vc4.html (this is for vc4 & some v3d)
https://www.kernel.org/doc/html/v5.2/gpu/v3d.html Well written
Hardware
Ref "The basic instruction set (add/mul ALU dual issue, three delay slots et al.) remains the same as VideoCore IV QPU of Raspberry Pi Zero/1/2/3, and some units now perform differently"
Rpi4: "VideoCore VI QPU @ 500MHz: 500 [MHz] x 2 [slice] x 4 [qpu/slice] x 4 [physical core/qpu] x 2 [op/cycle] = 32 [Gflop/s]". as compared to Odroid C4: Mali G31 MP2 > 40 gflops
VideoCore IV doc as published by Broadcom https://docs.broadcom.com/doc/12358545
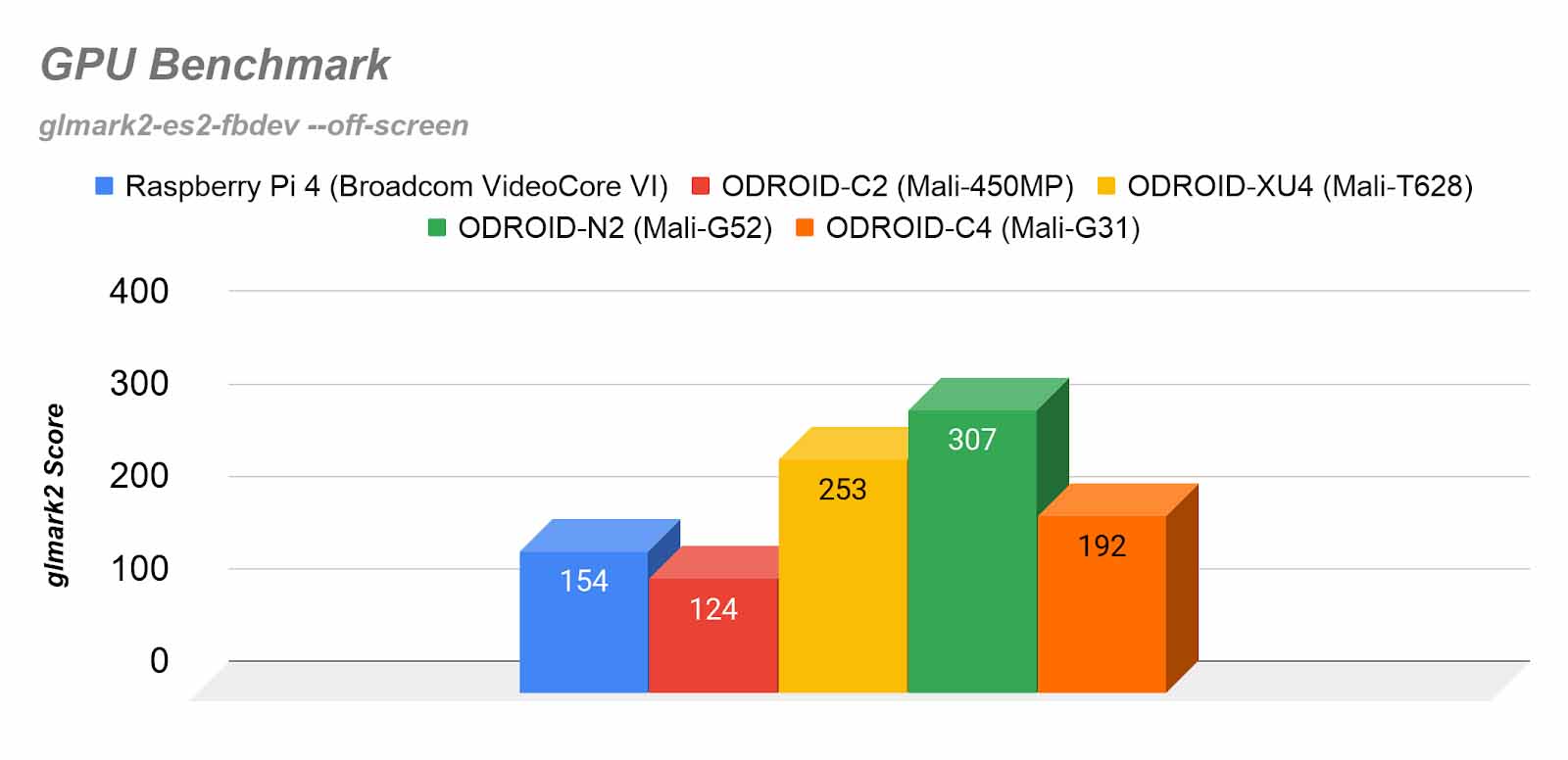
GPU benchmarks. Mali vs Videocore. by Odroid
ldunifrf -- load uniforms to any register
cf:
https://github.com/mesa3d/mesa/blob/master/src/broadcom/qpu/qpu_instr.c
Terms
About the GPU
V3D - the GPU for Rpi4.
VC4 - the GPUs for earlier Rpis (no MMU; less interesting)
CSD - Compute shader dispatch. This seems the major way for compute execution.
CL - command list (== control list? from clif_dump.c)
BO - buffer object, a term of DRM.
RCL - render command list. "In the V3D hardware, render command lists are what load and store tiles of a framebuffer and optionally call out to binner-generated command lists to do the 3D drawing for that tile."
BCL - binner command list. "The role of the Binning in the pipeline is enormous: It needs to find which tiles cover which primitives, or put another way, which primitives overlap which tiles"
cf: https://tayfunkayhan.wordpress.com/2019/07/26/chasing-triangles-in-a-tile-based-rasterizer/
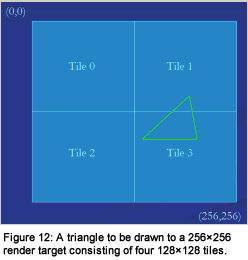
https://www.gamasutra.com/view/feature/4190/sponsored_feature_rasterization_.php?print=1
TFU - texture formatting unit
QPU -- Quad Processing Units, which is the GPU for Rpi4
TSDA - tile state data array. "The tile state data array is 48 bytes per tile, and we put it at the start of a BO containing both it and the tile alloc" (vc4_validate.c). Seems to pointed by qts. GPU binner will write to this??
PTB - Primitive Tile Binner
Render Nodes, eg /dev/dri/renderD128
"The "render nodes" concept tries to solve these scenarios by splitting the DRM user space API into two interfaces – one privileged and one non-privileged – and using separate device files (or "nodes") for each one.[9] For every GPU found, its corresponding DRM driver—if it supports the render nodes feature—creates a device file /dev/dri/renderDX, called the render node, in addition to the primary node /dev/dri/cardX.[54][9] Clients that use a direct rendering model and applications that want to take advantage of the computing facilities of a GPU, can do it without requiring additional privileges by simply opening any existing render node and dispatching GPU operations using the limited subset of the DRM API supported by those nodes—provided they have file system permissions to open the device file"
https://blogs.igalia.com/elima/tag/gpu/
GEM - a DRM term. "GEM stands for Graphics Execution Manager and is a generic DRM memory-management framework in the kernel". A good article: https://www.systutorials.com/docs/linux/man/7-drm-gem/
GBM - generic buffer manager. ""We now have a GBM device that is able to send commands to a GPU via its render-node interface" It wraps around the drm render node… good.
CLE - Control list executer
Overall design
The V3D GPU includes a tiled render (composed of a bin and render pipelines), the TFU (texture formatting unit), and the CSD (compute shader dispatch).
"Note that because CL validation is already reading the user-submitted CL and writing the validated copy out to the memory that the GPU will actually read, this is also where GEM relocation processing (turning BO references into actual addresses for the GPU to use) happens." --- Is this addr rewriting?
The GPU scheduling is interesting --- "For simplicity, and in order to keep latency low for interactive jobs when bulk background jobs are queued up, we submit a new job to the HW only when it has completed the last one, instead of filling up the CT[01]Q FIFOs with jobs"
"The compute shader dispatch interface is pretty simple -- just pass in the regs that userspace has passed us, with no CLs to run. However, with no CL to run it means that we need to do manual cache flushing of the L2 after the HW execution completes (for SSBO, atomic, and image_load_store writes that are the output of compute shaders)."

GPU stacks
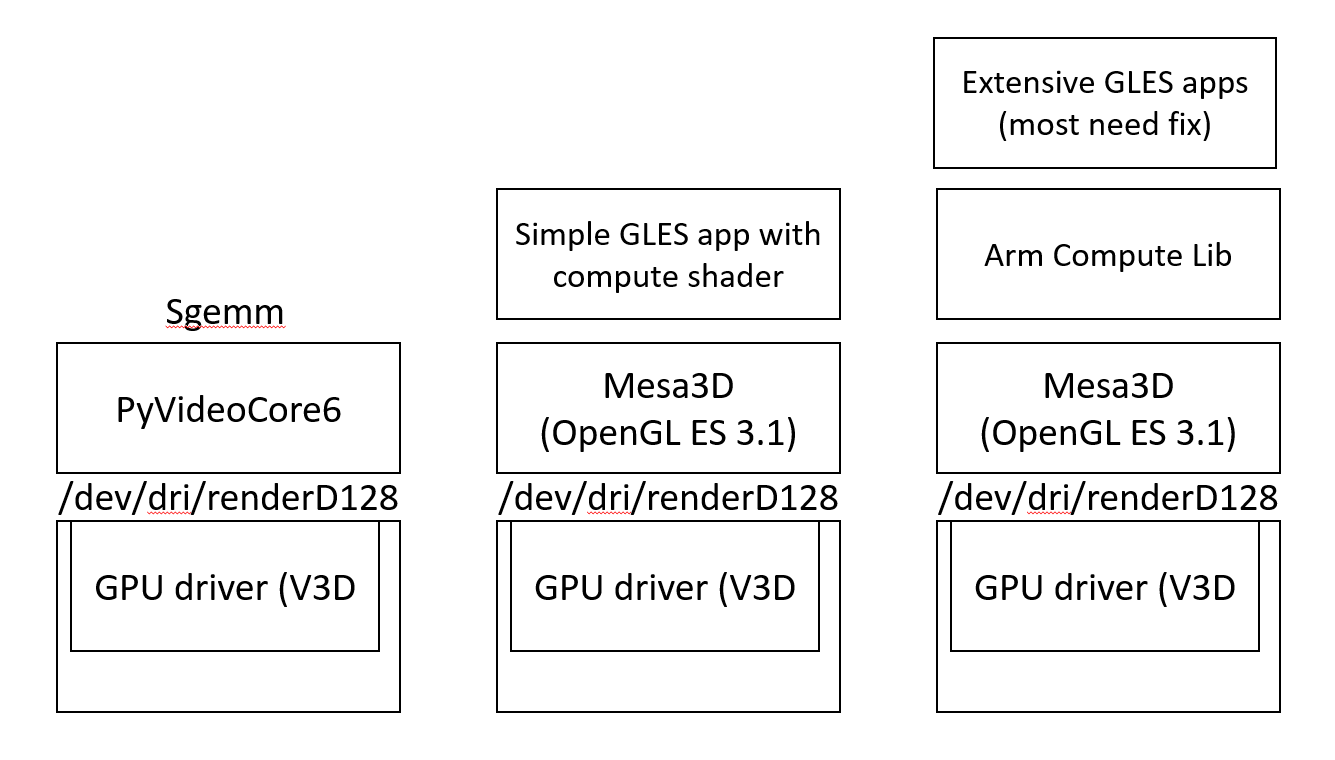
v3d vs vc4: both VideoCore IV (vc4) and VideoCore VI seem to use the same display pipeline. Hence, videocore VI depends on the pipeline driver found in vc4 driver. v3d is the name for the 3d engine.
cf: "Here's a (pretty long) series to introduce support in the VC4 DRM driver for the display pipeline found in the BCM2711 (and thus the RaspberryPi 4)."
https://lore.kernel.org/lkml/cover.dddc064d8bb83e46744336af67dcb13139e5747d.1599120059.git-series.maxime@cerno.tech/T/
Regs
device tree:
arch\arm\boot\dts\bcm2711-rpi.dtsi
v3d: v3d@7ec04000 {
compatible = "brcm,2711-v3d";
reg =
<0x7ec00000 0x0 0x4000>,
<0x7ec04000 0x0 0x4000>;
reg-names = "hub", "core0";
these seem "legacy addresses" as in bcm2711.
From /proc/iomem
fec00000-fec03fff : fec00000.v3d hub
fec04000-fec07fff : fec00000.v3d core0
From bcm2711 manual:
The peripheral addresses specified in this document are legacy master addresses. Software accessing peripherals using the DMA engines must use 32-bit legacy master addresses. The Main peripherals are available from 0x7C00_0000 to 0x7FFF_FFFF. Behind the scenes, the VideoCore transparently translates these addresses to the 35-bit 0x4_7nnn_nnnn addresses
So a peripheral described in this document as being at legacy address 0x7Enn_nnnn is available in the 35-bit address space at 0x4_7Enn_nnnn, and visible to the ARM at 0x0_FEnn_nnnn if Low Peripheral mode is enabled
for reg addrs, cf: v3d_regs.h
reg groups
regs are grouped. cf: v3d_debugfs.c. hub_regs; core_regs; bridge_regs; gca_regs;
reg mapping: v3d_platform_drm_probe()
-
hub - "for shared hardware between v3d cores"
-
core_regs: per core. max 3? (
void **__iomem** *core_regs[3];). only regs for core0 mapped -
gca_regs: not mapped when
v3d->ver < 41 - bridge: not mapped unless
**IS_ERR**(v3d->reset). why?
debugfs regs
code: "v3d_debugfs.c v3d_v3d_debugfs_regs()".
cat /sys/kernel/debug/dri/0/v3d_regs
V3D_HUB_AXICFG (0x0000): 0x0000000f
V3D_HUB_UIFCFG (0x0004): 0x00000045
V3D_HUB_IDENT0 (0x0008): 0x42554856
V3D_HUB_IDENT1 (0x000c): 0x000e1124
V3D_HUB_IDENT2 (0x0010): 0x00000100
V3D_HUB_IDENT3 (0x0014): 0x00000e00
V3D_HUB_INT_STS (0x0050): 0x00000000
V3D_HUB_INT_MSK_STS (0x005c): 0x00000005
V3D_MMU_CTL (0x1200): 0x060d0c01
V3D_MMU_VIO_ADDR (0x1234): 0x00000000
V3D_MMU_VIO_ID (0x122c): 0x00000000
V3D_MMU_DEBUG_INFO (0x1238): 0x00000550
core 0 V3D_CTL_IDENT0 (0x0000): 0x04443356
core 0 V3D_CTL_IDENT1 (0x0004): 0x81001422
core 0 V3D_CTL_IDENT2 (0x0008): 0x40078121
core 0 V3D_CTL_MISCCFG (0x0018): 0x00000006
core 0 V3D_CTL_INT_STS (0x0050): 0x00000000
core 0 V3D_CTL_INT_MSK_STS (0x005c): 0x00ff0058
core 0 V3D_CLE_CT0CS (0x0100): 0x00000000
core 0 V3D_CLE_CT0CA (0x0110): 0x0016000e
core 0 V3D_CLE_CT0EA (0x0108): 0x0016000e
core 0 V3D_CLE_CT1CS (0x0104): 0x00000000
core 0 V3D_CLE_CT1CA (0x0114): 0x0018005f
core 0 V3D_CLE_CT1EA (0x010c): 0x0018005f
core 0 V3D_PTB_BPCA (0x0300): 0x00083000
core 0 V3D_PTB_BPCS (0x0304): 0x00080000
core 0 V3D_GMP_STATUS (0x0800): 0x00000030
core 0 V3D_GMP_CFG (0x0804): 0x00000000
core 0 V3D_GMP_VIO_ADDR (0x0808): 0x00000000
core 0 V3D_ERR_FDBGO (0x0f04): 0x00000000
core 0 V3D_ERR_FDBGB (0x0f08): 0x00000010
core 0 V3D_ERR_FDBGS (0x0f10): 0x00000007
core 0 V3D_ERR_STAT (0x0f20): 0x00001000
core 0 V3D_CSD_STATUS (0x0900): 0x00000010
core 0 V3D_CSD_CURRENT_CFG0 (0x0920): 0x00200000
core 0 V3D_CSD_CURRENT_CFG1 (0x0924): 0x00010000
core 0 V3D_CSD_CURRENT_CFG2 (0x0928): 0x00010000
core 0 V3D_CSD_CURRENT_CFG3 (0x092c): 0x00000101
core 0 V3D_CSD_CURRENT_CFG4 (0x0930): 0xffffffff
core 0 V3D_CSD_CURRENT_CFG5 (0x0934): 0x00060005
core 0 V3D_CSD_CURRENT_CFG6 (0x0938): 0x00140000
reg access interface
cf: v3d_drv.h:
#define V3D_READ(offset) readl(v3d->hub_regs + offset)
#define V3D_WRITE(offset, val) writel(val, v3d->hub_regs + offset)
#define V3D_BRIDGE_READ(offset) readl(v3d->bridge_regs + offset)
#define V3D_BRIDGE_WRITE(offset, val) writel(val, v3d->bridge_regs + offset)
#define V3D_GCA_READ(offset) readl(v3d->gca_regs + offset)
#define V3D_GCA_WRITE(offset, val) writel(val, v3d->gca_regs + offset)
#define V3D_CORE_READ(core, offset) readl(v3d->core_regs[core] + offset)
#define V3D_CORE_WRITE(core, offset, val) writel(val, v3d->core_regs[core] + offset)
Rpi4: only 1 GPU core (8 QPUs)
cat /sys/kernel/debug/dri/0/v3d_ident
Revision: 4.2.14.0
MMU: yes
TFU: yes
TSY: yes
MSO: yes
L3C: no (0kb)
Core 0:
Revision: 4.2
Slices: 2
TMUs: 2
QPUs: 8
Semaphores: 0
BCG int: 0
Override TMU: 0
BO, MMU
Each bo is a virtual region (for CPU and GPU?) phys pages may not be contig. In creating bo, user specifies the bo size, the kernel returns the bo addr (GPU virt addr), so that the user can "relocates" its kernel.
"Compared to VC4 (V3D 2.x), V3D 3.3 introduces an MMU between the GPU and the bus, allowing us to use shmem objects for our storage instead of CMA. Physically contiguous objects may still be imported to V3D, but the driver doesn’t allocate physically contiguous objects on its own"
why shmem? for cache?
"The V3D 3.x hardware (compared to VC4) now includes an MMU. It has a single level of page tables for the V3D’s 4GB address space to map to AXI bus addresses, thus it could need up to 4MB of physically contiguous memory to store the PTEs."
v3d_mmu_set_page_table() --> setting up the page table
"we load all BOs into the same 4GB address space"
struct v3d_bo wraps around drm_mm_node. seems to correspond to drm_mm_node ("struct drm_mm_node - allocated block in the DRM allocator")
page size: 4KB. pte format: pfns shifted to lower bits
#define **V3D_MMU_PAGE_SHIFT** 12
#define V3D_PTE_SUPERPAGE BIT(31)
#define V3D_PTE_WRITEABLE BIT(29)
#define V3D_PTE_VALID BIT(28)
v3d_mmu_insert_ptes() very simple. populating PTEs. (recall this is a one lv pgtable)
Mesa: v3dv_bo_alloc() (not v3d_bo_alloc)
v3dv_bo.
bo->map: the CPU virt addr (returned by mmap);
bo->offset: addr in V3D space. returned from ioctl DRM_IOCTL_V3D_CREATE_BO. cf: v3dv_bo_init()
* Returned offset for the BO in the V3D address space. This offset
* is private to the DRM fd and is valid for the lifetime of the GEM
* handle.
*
* This offset value will always be nonzero, since various HW
* units treat 0 specially.
IOCTL
uapi/drm/v3d_drm.h
#define DRM_IOCTL_V3D_SUBMIT_CL DRM_IOWR(DRM_COMMAND_BASE + DRM_V3D_SUBMIT_CL, struct drm_v3d_submit_cl)
#define DRM_IOCTL_V3D_WAIT_BO DRM_IOWR(DRM_COMMAND_BASE + DRM_V3D_WAIT_BO, struct drm_v3d_wait_bo)
#define DRM_IOCTL_V3D_CREATE_BO DRM_IOWR(DRM_COMMAND_BASE + DRM_V3D_CREATE_BO, struct drm_v3d_create_bo)
#define DRM_IOCTL_V3D_MMAP_BO DRM_IOWR(DRM_COMMAND_BASE + DRM_V3D_MMAP_BO, struct drm_v3d_mmap_bo)
#define DRM_IOCTL_V3D_GET_PARAM DRM_IOWR(DRM_COMMAND_BASE + DRM_V3D_GET_PARAM, struct drm_v3d_get_param)
#define DRM_IOCTL_V3D_GET_BO_OFFSET DRM_IOWR(DRM_COMMAND_BASE + DRM_V3D_GET_BO_OFFSET, struct drm_v3d_get_bo_offset)
#define DRM_IOCTL_V3D_SUBMIT_TFU DRM_IOW(DRM_COMMAND_BASE + DRM_V3D_SUBMIT_TFU, struct drm_v3d_submit_tfu)
#define DRM_IOCTL_V3D_SUBMIT_CSD DRM_IOW(DRM_COMMAND_BASE + DRM_V3D_SUBMIT_CSD, struct drm_v3d_submit_csd)
#define DRM_V3D_SUBMIT_CL_FLUSH_CACHE 0x01
Noteworthy: DRM_IOCTL_V3D_SUBMIT_CSD
related:
v3d_submit_csd_ioctl()
Job submission, scheduling, etc.
A GPU program: setting up threads, etc; compiling the GPU program (shaders)
key functions:
py-videocore6 runtime
sample output
debian@debian-rpi64:~/rpi4-workspace/py-videocore6$ ./run.sh
xzl: fd 3 size 34603008 flags 0
xzl: create a bo. v3d addr: 04c40000 size: 02100000
xzl: skip CPU exec
xzl: unif_params [[ 512 1024 256 81002496 4096 85196800
4096 89391104 4096 1071762552 1053614440]
[ 512 1024 256 81002496 4096 85197824
4096 89392128 4096 1071762552 1053614440]
[ 512 1024 256 81002496 4096 85198848
4096 89393152 4096 1071762552 1053614440]
[ 512 1024 256 81002496 4096 85199872
4096 89394176 4096 1071762552 1053614440]
[ 512 1024 256 83099648 4096 85196800
4096 91488256 4096 1071762552 1053614440]
[ 512 1024 256 83099648 4096 85197824
4096 91489280 4096 1071762552 1053614440]
[ 512 1024 256 83099648 4096 85198848
4096 91490304 4096 1071762552 1053614440]
[ 512 1024 256 83099648 4096 85199872
4096 91491328 4096 1071762552 1053614440]]
xzl: unif to GPU [93585408 11]
==== sgemm example (1024x1024 times 1024x1024) ====
numpy: 0.0001086 sec, 1.981e+04 Gflop/s
QPU: 0.5602 sec, 3.839 Gflop/s
Minimum absolute error: 4.231929779052734e-06
Maximum absolute error: 268.70703125
Minimum relative error: 2.133229463652242e-05
Maximum relative error: 20240386.0
"[drm:vc4_wait_bo_ioctl [vc4]] Failed to look up GEM BO 34603008. " /boot/config.txt problem. See below.
driver.py -> a generic driver layer. HAL
class Driver: assemble shader program(s), calculate memory layout, and dispatch the shaders
program(): allocates a mem region (Array) from BO. assembles shader. fills shader code in Array
alloc(): allocate a buffer in BO's current data_pos. sequentially allocation.
class Memory: wraps around a DRM BO.
class Array: wraps around a memory region for GPU
drm_v3d.py-> low-level device syscall interface
v3d_create_bo() calls ioctl, which goes to a kernel func: v3d_create_bo_ioctl. ioctl, kernel func: v3d_create_bo_ioctl() args: drm_v3d_create_bo. it will return the offset for the BO in V3D addr space
kernel code: args->offset = bo->node.start << PAGE_SHIFT;
(bo->node.start seems CPU's virt page number? Not GPU's, as PAGE_SHIFT is for CPU). Update: it's GPU's
v3d_mmap_bo() through ioctl DRM_V3D_MMAP_BO later, mmap() (pass in the "fake" offset, get an addr) maps the BO to user address space In kernel: v3d_mmap_bo_ioctl().
wraps around drm_gem_create_mmap_offset()
* drm_gem_create_mmap_offset - create a fake mmap offset for an object
* @obj: obj in question
*
* GEM memory mapping works by handing back to userspace a fake mmap offset
* it can use in a subsequent mmap(2) call. The DRM core code then looks
* up the object based on the offset and sets up the various memory mapping
* structures.
assembler.py -- the mini assembler
sgemm.py
cpu execution: compile program; allocate memory; sgemm_rnn_naive() -- create 8 threads (QPU threads. total 8 QPUs)
qpu execution path: qpu_sgemm_rnn_naive() entry for each qpu thread, carrying a thread id;
-> load_params(): loads params and values
summation.py
mesa runtime
NB: v3d is the v3d driver for opengl? v3dv is the v3d driver for vulkan
/home/xzl/mesa/src/gallium/drivers/v3d/v3dx_draw.c
v3d_launch_grid() -> v3d_submit_csd_ioctl()
create/sched csd job w/ the DRM framework….
e.g. drm_sched_entity_push_job() / Submit a job to the entity's job queue /
cf v3d_push_job()…. do not fully understand. using dma fence for sync.
each v3d fence has a seq no… for testing? (do not have to fully understand. can pursue later)
grab a per-device sched lock when pushing job….
/* Lock taken when creating and pushing the GPU scheduler
\* jobs, to keep the sched-fence seqnos in order. */
**struct mutex sched_lock;**
// a csd job…
struct v3d_csd_job {
struct v3d_job base;
u32 timedout_batches;
struct drm_v3d_submit_csd args;
};
struct drm_v3d_submit_csd (kernel v3d_drm.h) contains parameters of the job (to be read by the kernel. some got pushed to GPU)
v3d_ioctl(DRM_IOCTL_V3D_SUBMIT_CSD) actual send it to harware, kick the job, etc
kernel
job configs (from userspace) are written to the config regs, see drivers/gpu/drm/v3d/v3d_regs.h
#define V3D_CSD_QUEUED_CFG0
#define V3D_CSD_QUEUED_CFG1
…
/* Number of batches, minus 1 */
#define V3D_CSD_QUEUED_CFG4 0x00914
/* Shader address, pnan, singleseg, threading, like a shader record. */
#define V3D_CSD_QUEUED_CFG5 0x00918
/* Uniforms address (4 byte aligned) */
#define V3D_CSD_QUEUED_CFG6
Side note on CFG[] semantics. CFG0-4 are parameters. CFG5 code addr OR bunch of flag bits (at least bits 0/1/2). cf mesa v3dv_cmd_buffer.c
#define V3D_CSD_CFG5_PROPAGATE_NANS (1 << 2)
#define V3D_CSD_CFG5_SINGLE_SEG (1 << 1)
#define V3D_CSD_CFG5_THREADING (1 << 0)
...
submit->cfg[5] = variant->assembly_bo->offset;
submit->cfg[5] |= V3D_CSD_CFG5_PROPAGATE_NANS;
if (variant->prog_data.base->single_seg)
submit->cfg[5] |= V3D_CSD_CFG5_SINGLE_SEG;
if (variant->prog_data.base->threads == 4)
submit->cfg[5] |= V3D_CSD_CFG5_THREADING;
Pyvideo6 does not fill in these lower bits. cf:
cfg=[
# WGS X, Y, Z and settings
wg_x << 16,
wg_y << 16,
wg_z << 16,
((roundup(wgs_per_sg * wg_size, 16) - 1) << 12) |
(wgs_per_sg << 8) |
(wg_size & 0xff),
# Number of batches minus 1
thread - 1,
# Shader address, pnan, singleseg, threading
code.addresses()[0],
# Uniforms address
uniforms if uniforms is not None else 0,
],
CFG6 is the GPU addr of the uniforms
submit->cfg[6] = uniforms.bo->offset + uniforms.offset;
v3d_mmap_bo_ioctl
mapping V3D BOs. "doesn't acctually perform an mmap. instead. .. returns the offset you need to use in an mmap on the DRM device node" (subsequent calls, to eventually map BO in user addr space)
v3d_wait_bo_ioctl
"waiting for completion of the last DRM_v3D_SUBMIT_CL on a BO" ... "wait for all rendering" on a BO to complete.
v3d_submit_cl_ioctl
"submitting commands to the 3D engine"
"This is the main entrypoint for userspace to submit a 3D frame to the GPU. Userspace provides the binner command list (if applicable), and the kernel sets up the render command list to draw to the framebuffer described in the ioctl, using the command lists that the 3D engine's binner will produce."
struct drm_v3d_submit_cl ... useful comments
/* Pointer to the binner command list.
*
* This is the first set of commands executed, which runs the
* coordinate shader to determine where primitives land on the screen,
* then writes out the state updates and draw calls necessary per tile
* to the tile allocation BO.
*
* This BCL will block on any previous BCL submitted on the
* same FD, but not on any RCL or BCLs submitted by other
* clients -- that is left up to the submitter to control
* using in_sync_bcl if necessary.
*/
/* Offset of the render command list.
*
* This is the second set of commands executed, which will either
* execute the tiles that have been set up by the BCL, or a fixed set
* of tiles (in the case of RCL-only blits).
*
* This RCL will block on this submit's BCL, and any previous
* RCL submitted on the same FD, but not on any RCL or BCLs
* submitted by other clients -- that is left up to the
* submitter to control using in_sync_rcl if necessary.
*/
Goes to: trace_v3d_submit_cl
v3d_submit_csd_ioctl
Submit a compute shader to dispatch
v3d_XXX_job
create/sched csd job w/ the DRM framework…. e.g. drm_sched_entity_push_job() / Submit a job to the entity's job queue /
cf v3d_push_job()…. do not fully understand. using dma fence for sync. each v3d fence has a seq no… for testing? (do not have to fully understand. can pursue later)
grab a per-device sched lock when pushing job….
/* Lock taken when creating and pushing the GPU scheduler jobs, to keep the sched-fence seqnos in order. */
struct mutex sched_lock;
v3d_sched_ops
submitting job to hardware. v3d_sched.c --- all v3d sched code as callbacks. cf v3d_csd_sched_ops, v3d_csd_job_run invoked by drm framework (gpu scheduler). triggered by the completion of the previous job (via dma fence)
v3d_csd_job_run()
actual send it to harware, set the conffig, kick the job, etc
registered as DRM callback … to be invoked by DRM framework. etc
job data structures
struct v3d_job (base); fences: irq_fence, done_fence.
--> struct v3d_bin_job; v3d_render_job, v3d_csd_job, v3d_tfu_job
struct v3d_dev holds pointers to each of the job type. (at most one outstanding job per type?)
v3d_fence. a wrapper around dma_fence
one fence ptr per job type. the fence is created for each job instance.
IRQ path
Quite simple.
v3d_irq() --> check nature of the irq. if csd completion, signal the dma fence (?) so that the next job will be dispatched(?)
/* v3d fence to be signaled by IRQ handler when the job is complete. */
dma_fence_signal(&fence->base);
dma_fence >>> v3d_fence
Command list/buffer
emit_rcl_prologue -> cl_emit (repeat) -> cl_emit(rcl, END_OF_RENDERING, end)
lack of documentation. most related - broadcom's opengl driver in mesa:
v3d_packet_v21.xml; v3d_packet_v33.xml; generated to .h with gen_pack_header.py --> v3d_packet_vXX_pack.h (e.g. v3d_pack_v42_pack.h)
v3d_packet_helpers.h (accessors)
v3dv_cl.h: cl_emit(), ..., cl_packet_pack(), cl_packet_struct ...
"packet" unpacked (as in C struct) and pack/unpack functions (to/from GPU mem?) example:
struct V3D42_FLAT_SHADE_FLAGS
inline void V3D42_FLAT_SHADE_FLAGS_pack(). five bytes ...
inline void V3D42_FLAT_SHADE_FLAGS_unpack()
#define V3D42_FLAT_SHADE_FLAGS_length 5
struct V3D42_FLUSH {...}
inline V3D42_FLUSH_pack() ...
#define V3D42_FLUSH_length 1
// common ones:
V3D42_END_OF_LOADS
Tracing & debugging
sample trace from Willems's computeheadless example: here
kernel: drm msgs:
echo 0x1ff > /sys/module/drm/parameters/debug
# off
echo 0 > /sys/module/drm/parameters/debug
https://www.lynxbee.com/how-to-enable-drm-driver-debug-logging-in-linux/
ftrace: collection
Useful trace events
ls /sys/kernel/debug/tracing/events/v3d
enable v3d_cache_clean_begin v3d_rcl_irq v3d_submit_cl v3d_submit_csd_ioctl v3d_tfu_irq
filter v3d_cache_clean_end v3d_reset_begin v3d_submit_cl_ioctl v3d_submit_tfu
v3d_bcl_irq v3d_csd_irq v3d_reset_end v3d_submit_csd v3d_submit_tfu_ioctl
sudo su
# clean
echo > /sys/kernel/debug/tracing/trace
# enable all
echo 1 > /sys/kernel/debug/tracing/events/v3d/enable
cat /sys/kernel/debug/tracing/events/v3d/enable
# selective enable
echo 0 > /sys/kernel/debug/tracing/events/v3d/enable
# irq
echo 1 > /sys/kernel/debug/tracing/events/v3d/v3d_bcl_irq/enable
echo 1 > /sys/kernel/debug/tracing/events/v3d/v3d_csd_irq/enable
echo 1 > /sys/kernel/debug/tracing/events/v3d/v3d_rcl_irq/enable
echo 1 > /sys/kernel/debug/tracing/events/v3d/v3d_tfu_irq/enable
# job submission
echo 1 > /sys/kernel/debug/tracing/events/v3d/v3d_submit_cl/enable
echo 1 > /sys/kernel/debug/tracing/events/v3d/v3d_submit_csd/enable
echo 1 > /sys/kernel/debug/tracing/events/v3d/v3d_submit_tfu/enable
# check
cat /sys/kernel/debug/tracing/trace
ftrace: Interpretation
Sample output 1
root@debian-rpi64:/mnt# cat /sys/kernel/debug/tracing/trace
# tracer: nop
#
# entries-in-buffer/entries-written: 15/15 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
gl3_cs_basic-3849 [000] .... 9580.128583: v3d_submit_csd_ioctl: dev=0, CFG5 0x00020565, CFG6 0x000c0000
v3d_csd-205 [002] .... 9580.128715: v3d_submit_csd: dev=0, seqno=2
<idle>-0 [000] d.h1 9580.129004: v3d_csd_irq: dev=0, seqno=2
v3d_cache_clean-206 [000] .... 9580.129057: v3d_cache_clean_begin: dev=0
v3d_cache_clean-206 [000] .... 9580.136846: v3d_cache_clean_end: dev=0
gl3_cs_basic-4276 [000] .... 11098.226732: v3d_submit_csd_ioctl: dev=0, CFG5 0x00020565, CFG6 0x000c0000
v3d_csd-205 [002] .... 11098.226909: v3d_submit_csd: dev=0, seqno=3
gl3_cs_basic-4276 [000] d.h1 11098.227193: v3d_csd_irq: dev=0, seqno=3
v3d_cache_clean-206 [000] .... 11098.227245: v3d_cache_clean_begin: dev=0
v3d_cache_clean-206 [000] .... 11098.235002: v3d_cache_clean_end: dev=0
gl3_cs_basic-4292 [003] .... 11106.656363: v3d_submit_csd_ioctl: dev=0, CFG5 0x00020565, CFG6 0x000c0000
v3d_csd-205 [002] .... 11106.656484: v3d_submit_csd: dev=0, seqno=4
strace-4289 [000] d.h1 11106.656770: v3d_csd_irq: dev=0, seqno=4
v3d_cache_clean-206 [000] .... 11106.656822: v3d_cache_clean_begin: dev=0
v3d_cache_clean-206 [000] .... 11106.664537: v3d_cache_clean_end: dev=0
Sample output 2
# tracer: nop
#
# entries-in-buffer/entries-written: 15/15 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
computeheadless-1328 [002] .... 8599.396681: v3d_submit_cl_ioctl: dev=1, RCL 0x00140000..0x0014005f
v3d_bin-252 [002] .... 8599.396804: v3d_submit_cl: dev=1, BCL, seqno=42, 0x00060000..0x0006000e
<idle>-0 [000] d.h1 8599.396818: v3d_bcl_irq: dev=1, seqno=42
v3d_render-253 [001] .... 8599.396918: v3d_submit_cl: dev=1, RCL, seqno=42, 0x00140000..0x0014005f
<idle>-0 [000] d.h1 8599.396933: v3d_rcl_irq: dev=1, seqno=42
computeheadless-1328 [002] .... 8599.446883: v3d_submit_csd_ioctl: dev=1, CFG5 0x00060005, CFG6 0x00140000
computeheadless-1328 [002] .... 8599.446972: v3d_submit_cl_ioctl: dev=1, RCL 0x00180000..0x0018005f
v3d_csd-256 [000] .... 8599.446991: v3d_submit_csd: dev=1, seqno=40
v3d_bin-252 [002] .... 8599.447058: v3d_submit_cl: dev=1, BCL, seqno=43, 0x00160000..0x0016000e
<idle>-0 [000] d.h1 8599.447070: v3d_bcl_irq: dev=1, seqno=43
<idle>-0 [000] d.h1 8599.447250: v3d_csd_irq: dev=1, seqno=40
v3d_cache_clean-257 [003] .... 8599.447288: v3d_cache_clean_begin: dev=1
v3d_cache_clean-257 [003] .... 8599.447335: v3d_cache_clean_end: dev=1
v3d_render-253 [001] .... 8599.447396: v3d_submit_cl: dev=1, RCL, seqno=43, 0x00180000..0x0018005f
<idle>-0 [000] d.h1 8599.447411: v3d_rcl_irq: dev=1, seqno=43
Brief explanation: v3d_submit_cl_ioctl() enters the kernel. In response, the driver submits two command lists. First BCL (seqno=42) and then RCL (seqno=42). Each CL receives its own irq.
-
v3d_submit_cl_ioctl: args->rcl_start ... args->rcl_end (addr?)
-
v3d_submit_cl: RCL (render command list); BCL (binner cmd list) ... job.start .. job.end (what's this? TBD)
-
v3d_submit_csd_ioctl -- invoked at ioctl, when user sends the job to kernel. cfg5: code addr (? +other things?); cfg6: uniforms addr
-
uniforms seem parameters to threads (offsets to the input/output data) cf: py-videocore6 sgemm.py load_params
-
v3d_submit_csd -- invoked in
v3d_csd_job_run(), when job actually sent to hardware. seqno: v3dfence->seqno
code: v3d_trace.h
mesa
v3d_debug.c
export V3D_DEBUG=cl
Then run vulkan apps. Possible options (v3d_debug.c)
static const struct debug_control debug_control[] = {
{ "cl", V3D_DEBUG_CL},
{ "clif", V3D_DEBUG_CLIF},
{ "qpu", V3D_DEBUG_QPU},
{ "vir", V3D_DEBUG_VIR},
{ "nir", V3D_DEBUG_NIR},
{ "tgsi", V3D_DEBUG_TGSI},
{ "shaderdb", V3D_DEBUG_SHADERDB},
{ "surface", V3D_DEBUG_SURFACE},
{ "perf", V3D_DEBUG_PERF},
{ "norast", V3D_DEBUG_NORAST},
{ "fs", V3D_DEBUG_FS},
{ "gs", V3D_DEBUG_GS},
{ "vs", V3D_DEBUG_VS},
{ "cs", V3D_DEBUG_CS},
{ "always_flush", V3D_DEBUG_ALWAYS_FLUSH},
{ "precompile", V3D_DEBUG_PRECOMPILE},
{ "ra", V3D_DEBUG_RA},
{ "dump_spirv", V3D_DEBUG_DUMP_SPIRV},
{ NULL, 0 }
};
some note: NIR: a new mesa IR (looks like mesa v3d for GL is using it); VIR: virGL?
invoke spirv-dis to disassemble Vulkan IR. Nothing special
v3d_debug.c (for debugging low-level v3d functions?)
qpu_disasm.c v3d_dump_qpu() disassemble qpu code?
clif? CL interface debug output? (common for vc4 and v3d)
v3dv_clif_dump() --> dump cl?
"The final result was a CLIF file I sent to the HW team..." here
V3D_DEBUG (v3d_debug.c) -- a global var for controlling debugging.
v3d_job_submit()->v3d_clif_dump(v3dv_queue.c)->clif_dump_init() --> ... clif_dump(the core func, from v3d code)
v3dv_clif_dump()->clif_dump_init() --> ...
clif_dump_cl->clif_dump_packet->v3d42_clif_dump_packet
defined in v3dx_dump.c: v3dX(clif_dump_packet)(struct clif_dump *clif, uint32_t offset, ....)
each "packet": an instruction spanning multiple bytes? name: from .xml "short name", convert to upper case, with underscore between words.
e.g. name="Tile Rendering Mode Cfg (Common)" ---> TILE_RENDERING_MODE_CFG_COLOR
cf clif_name()
struct reloc_worklist_entry. reloc record? This seems how each BO is parsed into multiple parts (buffers, ctrllist, etc.) how is it done?
Interpreting the trace
func: clif_dump() <--- handle_cl_job() every time DRM_IOCTL_V3D_SUBMIT_CL (a CL job is submitted)
- @createbuf_aligned dump all BO allocations ref'd in the CL
- (repeat) @buffer dump contents of all BOs, in their "reloc" addr order. Then dump BOs w/o reloc information
- @add_bin dump bin CL summary
- @add_render dump render CL summary
order: reloc records? sorted by reloc_worklist_entry->addr
@createbuf_aligned 4096 device_alloc_0x20000
creation of BO & its name. Only BOs referenced in CL are traced? (i.e. there can be more BOs)
BO name: in v3dv_clif_dump. name + bo->offset (offset is GPU addr)
@buffer CL_0x60000
@format ctrllist
@buffer -- mark the start of a BO.
@format ctrllist - starting dumping packets of this CL.
followed by a list of packets. decoded.
@format binary: raw data? not to be parsed as CL packets.
@format blank 4001 /* [CL_0x140000+0x0000005f..0x00000fff] */ empty (all zeros) data. its size & starting/end addr
code: clif_dump() submit a CL to the GPU for execution. the CL (bin and render) is already populated in BO. info from @struct drm_v3d_submit_cl.
@add_bin 0
[CL_0x160000+0x00000000] /* 0x00160000 */ # bcl start
[CL_0x160000+0x0000000e] /* 0x0016000e */ # bcl end
[tile_alloc_0x80000+0x00000000] /* 0x00080000 */ # qma, offset of tile alloc mem, --> reg V3D_CLE_CT0QMA
536576 # qms, size of tile alloc mem --> reg V3D_CLE_CT0QMS
[TSDA_0x120000+0x00000000] /* 0x00120000 */ # qts, offset of tile state data array
@wait_bin_all_cores
@add_render 0
[CL_0x180000+0x00000000] /* 0x00180000 */ # rcl start
[CL_0x180000+0x0000005f] /* 0x0018005f */ # rcl end
[tile_alloc_0x80000+0x00000000] /* 0x00080000 */ # qma, see above
@wait_render_all_cores
CL_0x160000, tile_alloc_0x80000, etc: the BO name. also encoded BO base address
v3dv_bo.c
static const bool dump_stats = true; // false;
User frameworks
Kompute
Python/C++ to wrap around Vulkan. It works!
https://kompute.cc/overview/python-examples.html
Arm Compute Library
gc_dc
GC: GLES_compute DC: direct convolution
void GCKernel::update_shader_params()
{
/* xzl: this seems to compare the shader's params size (_shader_params_size,
as returned by OGL runtime, which is from shader's compiler?) with the
expected _shader_arguments size as prepared by the host program.
On a3d, for some shader (e.g. direct_convolution3x3), there's a mismatch
(128. vs 120) while other shaders seem fine. Guess: A3D's compiler (Mesa/llvm?)
generates 8-byte aligned parameters?
*/
std::cout << "xzl: update_shader_params() on kernel " << name() << " _shader_arguments.size() " << _shader_arguments.size() << std::endl;
ARM_COMPUTE_ERROR_ON_MSG_VAR((_shader_params_size != (int)(_shader_arguments.size() * sizeof(_shader_arguments[0]))), "Arguments size (%zu) is not equal to shader params block size (%d)",
_shader_arguments.size() * sizeof(_shader_arguments[0]), _shader_params_size);
AlexNet
./build/examples/graph_alexnet
ERROR in create_subtensor src/graph/backends/GLES/GCDeviceBackend.cpp:122: GLES backend has no sub-tensor support!
seems this func is not implemented in GLES (ACL's problem)
./build/examples/graph_lenet
./build/examples/graph_googlenet
./build/examples/graph_mnist
!!!!!!!!!!!!!!!!!!!!!!!!!!!
ERROR in configure src/runtime/GLES_COMPUTE/functions/GCConvolutionLayer.cpp:97: weights->info()->dimension(2) != input->info()->dimension(2) No such file or directory
!!!!!!!!!!!!!!!!!!!!!!!!!!!
MobileNet
./build/examples/graph_mobilenet
ERROR in validate_all_nodes src/graph/detail/ExecutionHelpers.cpp:51: in validate src/graph/backends/GLES/GCNodeValidator.cpp:136: Unsupported operation : ReshapeLayer
sequzzenet FlattenLayer unsupported
Howto
Kernels
tested on 32bit (5.4) or 64bit (4.19)
py-videocore6 seems to break w/o the following:
$ more /boot/config.txt
dtoverlay=vc4-fkms-v3d
Mesa-v3dv
Build
(OBSOLETED): Debian 10. rpi64.
Following instructions here:
https://blogs.igalia.com/apinheiro/2020/06/v3dv-quick-guide-to-build-and-run-some-demos/
except that python-mako no longer exists (so don't install it). And meson's path is ~/.local/bin/meson. Everything should install & build fine.
Rapsbian OS 64 bit. stock kernel 5.4
sudo apt-get install libxcb-randr0-dev libxrandr-dev \
libxcb-xinerama0-dev libxinerama-dev libxcursor-dev \
libxcb-cursor-dev libxkbcommon-dev xutils-dev \
xutils-dev libpthread-stubs0-dev libpciaccess-dev \
libffi-dev x11proto-xext-dev libxcb1-dev libxcb-*dev \
bison flex libssl-dev libgnutls28-dev x11proto-dri2-dev \
x11proto-dri3-dev libx11-dev libxcb-glx0-dev \
libx11-xcb-dev libxext-dev libxdamage-dev libxfixes-dev \
libva-dev x11proto-randr-dev x11proto-present-dev \
libclc-dev libelf-dev git build-essential mesa-utils \
libvulkan-dev ninja-build libvulkan1 python-mako \
libdrm-dev libxshmfence-dev libxxf86vm-dev \
python3-mako
sudo apt install cmake
Environment: Raspbian OS 32bit. stock kernel.
Linux raspberrypi 5.10.11-v7l+ #1399 SMP Thu Jan 28 12:09:48 GMT 2021 armv7l GNU/Linux
Follow the instructions above. Except use release and x11 only:
Configure + debug
meson --prefix /home/pi/local-install --libdir lib -Dplatforms=x11 -Dvulkan-drivers=broadcom -Ddri-drivers= -Dgallium-drivers=v3d,kmsro,vc4 -Dbuildtype=debug _build_debug
ninja -C _build_debug
ninja -C _build_debug install
Clean build + release
$ meson --wipe --prefix /home/pi/local-install --libdir lib -Dplatforms=x11 -Dvulkan -drivers=broadcom -Ddri-drivers= -Dgallium-drivers=v3d,kmsro,vc4 -Dbuildtype=release _build_release
export VK_ICD_FILENAMES=~/local-install/share/vulkan/icd.d/broadcom_icd.armv7l.json
# or
export VK_ICD_FILENAMES=~/local-install/share/vulkan/icd.d/broadcom_icd.aarch64.json
v3dv entry points:
v3dv_entrypoints.h. generated by "vk_entrypoints_gen.py"
buffer (BO)
device_alloc: "device memory". directly by Vulkan entry point v3dv_AllocateMemory.
for input/output?allocated in v3dv_AllocateMemory() -> device_alloc() (v3dv_device.c)
CL: for command lists
tile_alloc
TSDA: ??
sample v3dv log (V3D_DEBUG=cl) only shows BO allocations referenced by CLs. example
@createbuf_aligned 4096 device_alloc_0x20000
@createbuf_aligned 4096 device_alloc_0x40000
@createbuf_aligned 4096 CL_0x60000
@createbuf_aligned 4096 tile_alloc_0x80000
@createbuf_aligned 4096 TSDA_0x120000
@createbuf_aligned 4096 CL_0x140000
@createbuf_aligned 4096 CL_0x160000
Validate vulkan - some handy tools
apt install vulkan-tools
xdpyinfo | grep DRI3
vulkaninfo
vktube
# startx /usr/bin/vkcube
Validate vulkan - SaschaWillems vulkan benchmarks
must build with "export VK_ICD_FILENAMES ..."
must run from GUI (not command line) "Could not find a compatible Vulkan ICD!" Is it because we are running from cmdline.
"no DRI3 is found" (-- an xorg issue; a clean image of RpiOS solves the problem). Check Xorg log file
Out of host memory -- normal?
download assets
mkdir build; cd build
cmake -DCMAKE_BUILD_TYPE=Debug ..
make -j4
cf: build Unreal atop Vulkan for Rpi4
ncnn
https://qengineering.eu/install-ncnn-on-raspberry-pi-4.html
# mkdir Debug
cd Debug
# 32 bit, Debug mode
# cmake -DCMAKE_TOOLCHAIN_FILE=../toolchains/pi3.toolchain.cmake -DPI3=ON -DCMAKE_BUILD_TYPE=Debug ..
cmake -DCMAKE_BUILD_TYPE=Debug -DNCNN_VULKAN=ON -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON ..
# 32 bit, rls mode
cmake -DCMAKE_BUILD_TYPE=Release -DNCNN_VULKAN=ON -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON ..
#64 bit, debug
cmake -DCMAKE_BUILD_TYPE=Debug -DNCNN_VULKAN=ON -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON ..
make -j$(nproc)
run benchmark
export VK_ICD_FILENAMES=~/local-install/share/vulkan/icd.d/broadcom_icd.armv7l.json
# or aarch64.json
cd /data/rpi4-workspace/ncnn/benchmark
../Debug/benchmark/benchncnn 4 4 0 0
# or
../Debug64/benchmark/benchncnn 1 1 0 0 0
squeezenet
export VK_ICD_FILENAMES=/home/pi/local-install/share/vulkan/icd.d/broadcom_icd.armv7l.json
cd /data/rpi4-workspace/ncnn/examples
../Debug/examples/squeezenet ~/cat.jpg
pi@raspberrypi:/data/rpi4-workspace/ncnn/examples $ ../build/examples/squeezenet ~/cat.jpg
[0 V3D 4.2] queueC=0[1] queueG=0[1] queueT=0[1]
[0 V3D 4.2] bugsbn1=0 bugbilz=0 bugcopc=0 bugihfa=0
[0 V3D 4.2] fp16-p/s/a=1/0/0 int8-p/s/a=1/0/0
[0 V3D 4.2] subgroup=1000 basic=0 vote=0 ballot=0 shuffle=0
283 = 0.989258
21 = 0.003250
259 = 0.001511
../Release/examples/squeezenet ../images/256-ncnn.png
the initial CL (command list) jobs
where do they come from?
export VK_ICD_FILENAMES=/home/pi/local-install/share/vulkan/icd.d/broadcom_icd.armv7l.json
cd /data/rpi4-workspace/ncnn/benchmark
gdb ../Debug/benchmark/benchncnn
b handle_cl_job
b queue_create_noop_job
r 1 1 0 0 0
CL job path 1:
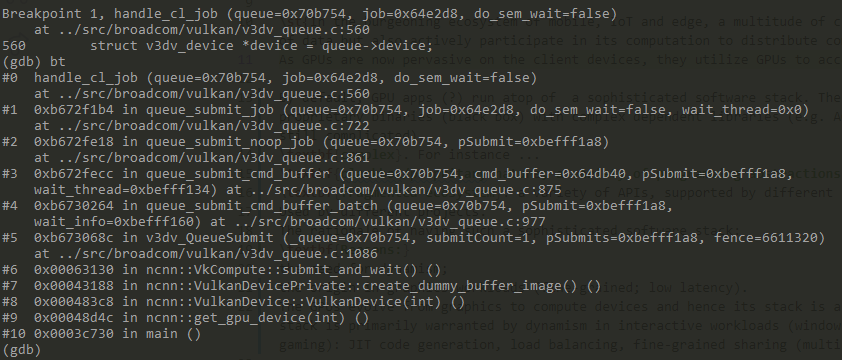
Mesa seems to queue a "noop" job if the cmd buffer (what is this?) is empty:
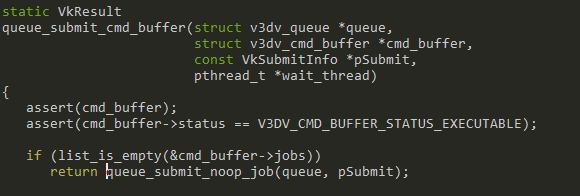
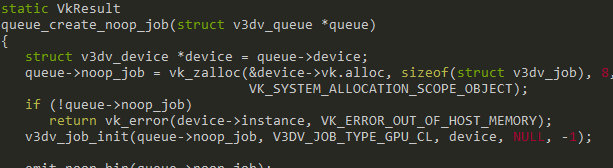
queue_submit_noop_job() creates a job type of GPU_CL, done by queue_create_noop_job
CL job path 2:
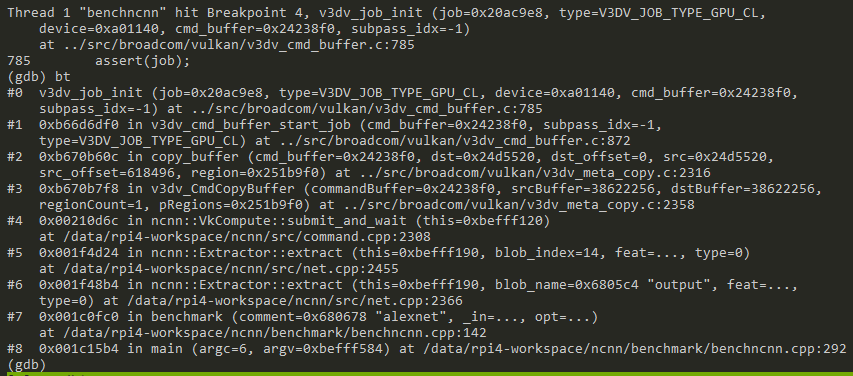
ncnn::Extractor (meaning data input/output?) -> generate Vk command -> cmd.record_download. meaning to record a download command. here, the download is from device mem to host mem
inside record_download(): create a "dst_staging" (VKMat on device mem). repacking data, download from dst_staging...
v3dv_CmdCopyBuffer (a vulkan command??) -> ... -> copy_buffer() will create a GPU_CL job (binning bcl for flush, render rcl for copy)
https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkCmdCopyBuffer.html
struct v3dv_job *job = NULL;
while (num_items > 0) {
job = v3dv_cmd_buffer_start_job(cmd_buffer, -1, V3DV_JOB_TYPE_GPU_CL);
if (!job)
return NULL;
v3dv_cmd_buffer_start_job/v3dv_cmd_buffer_finish_job -> starting/finishing populating a job.
CSD job path. From ncnn::VkCompute
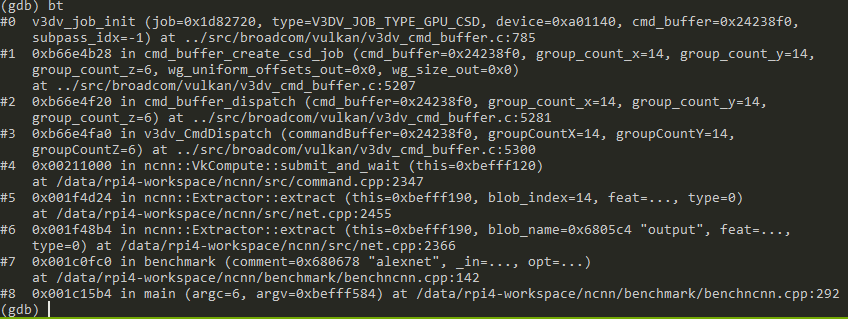
Misc
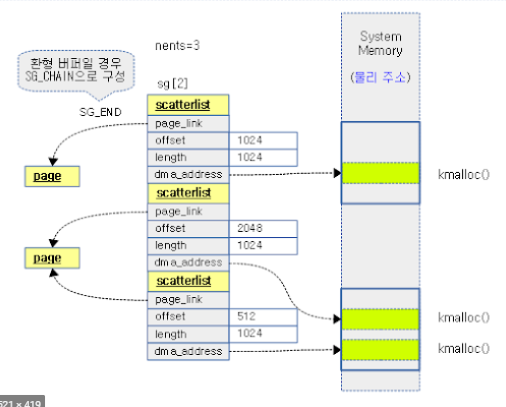
Scatter list
An sg is for a DMA region, for which the underlying phys memory do not have to be contig.
Each element in the sg correspond to a contig phys region
A good article https://lwn.net/Articles/256368/
"Within the kernel, a buffer to be used in a scatter/gather DMA operation is represented by an array of one or more scatterlist structures"
"A chained scatter/gather list can be made up of more than one page, and those pages, too, are likely to be scattered throughout physical memory"
meaning that the sg itself can span multiple pages.
A sgtable is really a "table"
A Nice figure (chaining not shown)