Jetson_nano
Spec
Tegra X1 SoC (TM660M)
- CPU: 4 A53 + 4 A57
- GPU: Maxwell-based (128 cores)
Note:
- Seems it gather multiple commands into a job but serialized with job unit
- No OpenCL support but CUDA
- Cannot find specific
Heejin's writeup:
https://bakhi.github.io/Jetson-nano/
Terms
gk20a -- the GPU gen of jetson tk1 (kepler)
gr3d - the GPU engine. ref
cde color decompression engine
cdma: command dma
command stream: a sequence of GPU reg IO written to host1x
channel: a FIFO to push commands to a client (i.e. a hw unit)
- Grate: Prior reverse engineering effort by record and replay syscalls (ioctl) at user/kernel interface
- Myriad cmd submission: seem to be dumped from cmd stream
Grate - prior effort for reverse engineering
-
Myriad cmd submission](https://github.com/grate-driver/grate/blob/master/tests/nvhost/gr3d.c): seem to be dumped from cmd stream
EXP Environment
- Use a simple test application (vector addition)
- Dump trace
- printk
- ftrace
Ftrace
Channel worker messes up the trace
It seems a separate channel worker thread puts or gets work item in the queue. Even no GPU apps run, the ftrace continuously prints out both gk20a_channel_put: channel 511 caller gk20a_channel_poll_timeouts and gk20a_channel_get: channel 511 caller gk20a_channel_poll_timeouts iteratively.
Achieve clean trace
The channel worker makes the entire trace messy. To get cleaned trace, follows some tips:
- Add the following functions to
set_ftrace_notrace - __nvgpu_log_dbg
- _gk20a_channel_put
- nvgpu_thread_should_stop
- nvgpu_cond_broadcast
- nvgpu_timeout_peek_expired
- nvgpu_platform_is_silicon
- Disable the following events from gk20a
- gk20a_channel_put
- gk20a_channel_get
- gk20a_channel_set_timeout
What to validate?
One to one matching (job:IRQ) - IRQ and sync by the wait command and fence
Does the GPU use page table? - yes
GPU state updates - unknown
Interrupt
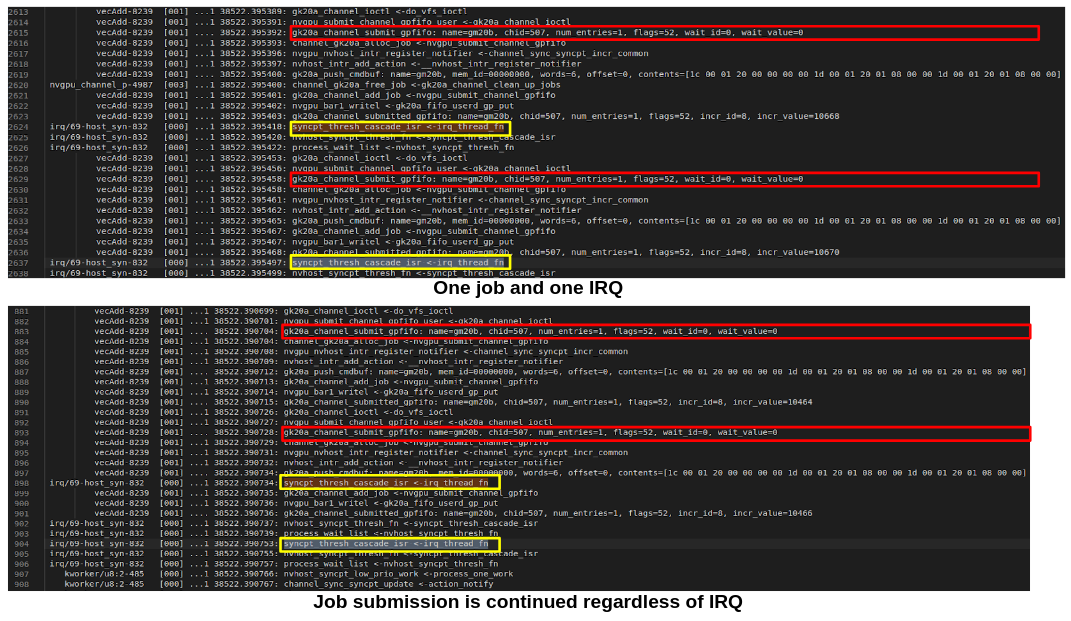
IRQ coalescing: IRQ after job (cmd) submission, but not 1:1 matching
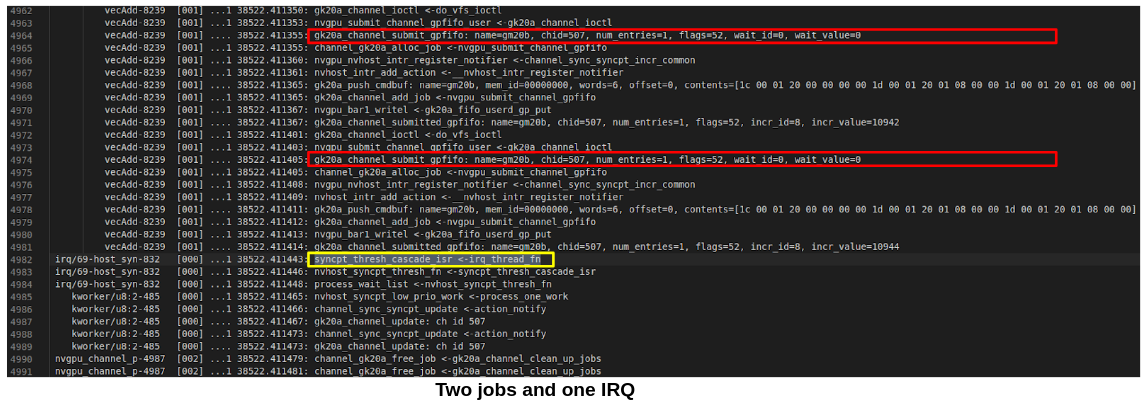
IRQ cascade: user-space keeps submitting jobs (writing command to FIFO buffer and hence the ringbuffer)
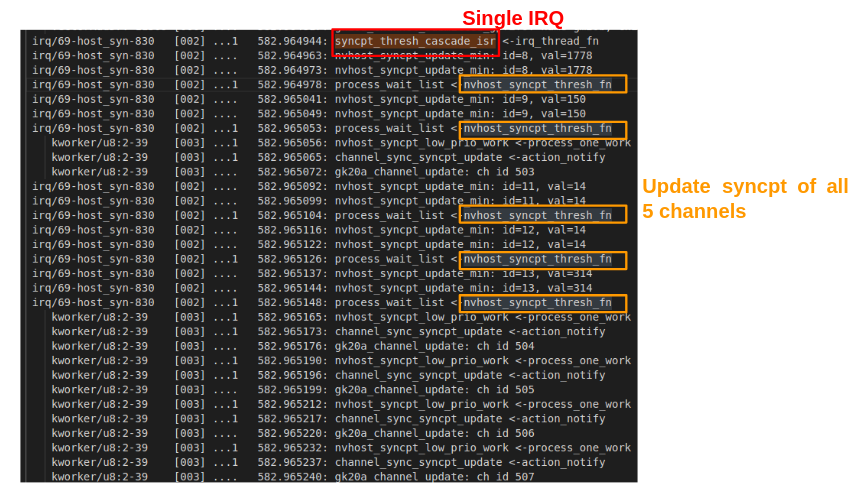
Inter-channel IRQ coalescing: possible for all the channels.
static irqreturn_t syncpt_thresh_cascade_isr(int irq, void *dev_id)
...
for_each_set_bit(id, ®, 32) {
...
irq semantics
syncpt_thresh_cascade_isr
ioctl
cf: kernel include/uapi/linux/nvhost_ioctl.h
NVHOST_IOCTL_CHANNEL_SUBMIT_EXT (7) --- no longer exists in the newest driver?
h1x
clients?
can be inferred from:
// include/linux/host1x.h
enum host1x_class {
HOST1X_CLASS_HOST1X = 0x1,
HOST1X_CLASS_GR2D = 0x51,
HOST1X_CLASS_GR2D_SB = 0x52,
HOST1X_CLASS_VIC = 0x5D,
HOST1X_CLASS_GR3D = 0x60,
};
enum host1x_class {
HOST1X_CLASS_HOST1X = 0x1,
HOST1X_CLASS_NVENC = 0x21,
HOST1X_CLASS_VI = 0x30,
HOST1X_CLASS_ISPA = 0x32,
HOST1X_CLASS_ISPB = 0x34,
HOST1X_CLASS_GR2D = 0x51,
HOST1X_CLASS_GR2D_SB = 0x52,
HOST1X_CLASS_VIC = 0x5D,
HOST1X_CLASS_GR3D = 0x60,
HOST1X_CLASS_NVJPG = 0xC0,
HOST1X_CLASS_NVDEC = 0xF0,
};
job synchronization
good refs:
(these may be outdated. should refer to "grate" code)
http://http.download.nvidia.com/tegra-public-appnotes/host1x.html "host1x hardware description"
https://lists.freedesktop.org/archives/dri-devel/2012-December/031410.html "First version of host1x intro"
kernel doc: https://www.kernel.org/doc/html/latest/gpu/tegra.html
fence is for sync. two types: semaphores (hw?) and syncpoints (??)
syncpt has id and value ("incr_id, incr_value"?). also called "increment"?
"pre-fence" and "post fence". key function: nvgpu_submit_prepare_syncs
Channels and Job Submission
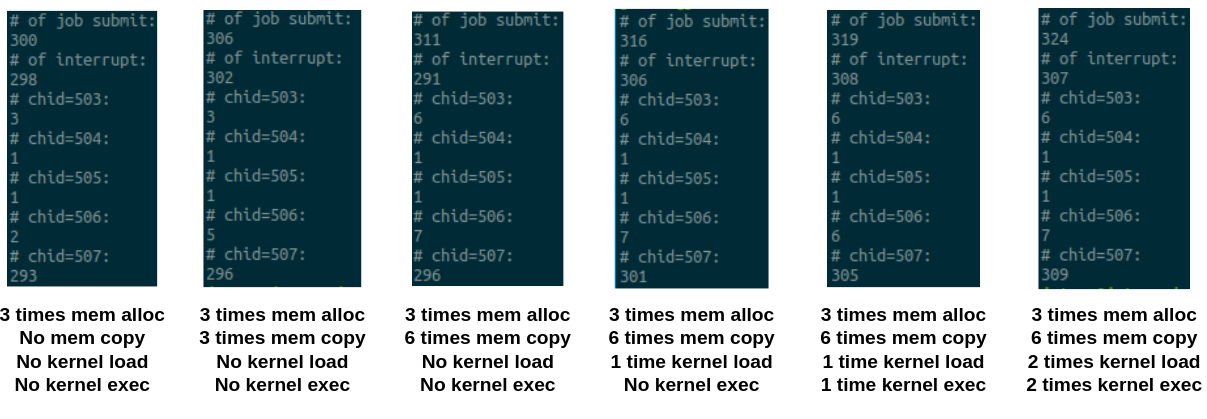
Observation
- Not many jobs submission from kernel execution
- ~ 300 jobs for init and term
- command is more fine-grained than atom structure in mali
- Even printf in the cuda kernel generates jobs
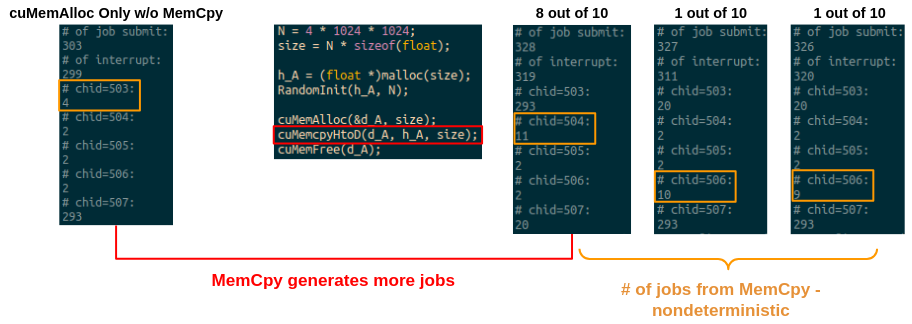
# of jobs is nondeterministic
- Default # of jobs: init + term = 303
- cuMemAlloc does not affect # of submitted jobs
- May affect together with MemCpy
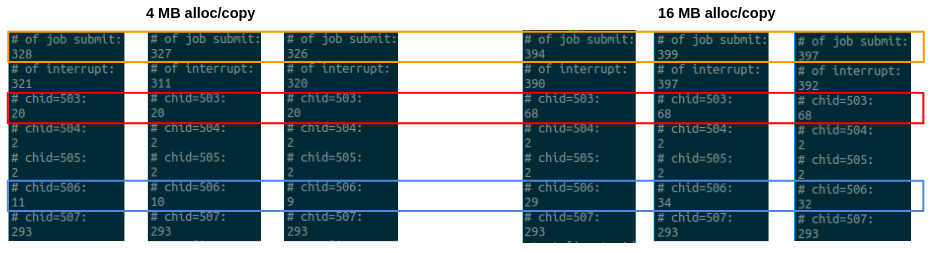
Impact of input size
-
The number of submitted jobs increases with larger input size
-
Guess
- Redbox: MemAlloc/Cpy channel - the same input size, the same # of jobs
- Bluebox: GPU state transition - may rely on execution time like the mali does in power regIO
Summary
Job execution
-
Context init and term generates ~300 jobs (deterministic)
-
Not many job submissions from kernel execution, but command stream is more fine-grained compared to Mali
atom structure
Memory
- MemAlloc does not add jobs but memCpy does
- Large MemCpy generates more jobs together with memAlloc
Channels
userspace created using:
#define NVGPU_GPU_IOCTL_OPEN_CHANNEL \
_IOWR(NVGPU_GPU_IOCTL_MAGIC, 11, struct nvgpu_gpu_open_channel_args)
The code suggests kernel will allocate channel id
struct nvgpu_gpu_open_channel_args {
union {
__s32 channel_fd; /* deprecated: use out.channel_fd instead */
struct {
/* runlist_id is the runlist for the
* channel. Basically, the runlist specifies the target
* engine(s) for which the channel is
* opened. Runlist_id -1 is synonym for the primary
* graphics runlist. */
__s32 runlist_id;
} in;
struct {
__s32 channel_fd;
} out;
};
};
when a channel is opened via ioctl, the kernel will grab a unused fd and create a userspace file (?) waiting to be opened by user. nvhost-dev-fdX...
static long nvhost_channelctl(struct file *filp,
unsigned int cmd, unsigned long arg) {
...
switch (cmd) {
case NVHOST_IOCTL_CHANNEL_OPEN:
{
...
err = __nvhost_channelopen(NULL, priv->pdev, file);
Observation from log
- Multiple channels are allocated for a single application running
- Each channel has its own ringbuffer
- ch 507 - for init? alwasy 293 jobs
- ch 503 - related to mem allocation task. # of submission grow with allocation sizes
- ch 506 - the source of non determinism. # of submission vary across runs - could be GPU state transitions (PM?), etc.
- ch 504/505?
Note: channel ID is nondeterministic
Delays
- May make execution deterministic
- 50 us delay makes one-to-one job execution but not always
Related project
https://github.com/grate-driver/grate/wiki/Grate-driver
helpful code. easy to read. be aware it's for ancient NV devices though. many IOCTLs are obsoleted